

{kind=link}
Pure language processing opened the door for semantic search on Google.
SEOs want to know the swap to entity-based search as a result of that is the way forward for Google search.
On this article, we’ll dive deep into pure language processing and the way Google makes use of it to interpret search queries and content material, entity mining, and extra.
What’s pure language processing?
Pure language processing, or NLP, makes it doable to know the which means of phrases, sentences and texts to generate info, information or new textual content.
It consists of pure language understanding (NLU) – which permits semantic interpretation of textual content and pure language – and pure language technology (NLG).
NLP can be utilized for:
- Speech recognition (textual content to speech and speech to textual content).
- Segmenting beforehand captured speech into particular person phrases, sentences and phrases.
- Recognizing primary types of phrases and acquisition of grammatical info.
- Recognizing capabilities of particular person phrases in a sentence (topic, verb, object, article, and so forth.)
- Extracting the which means of sentences and components of sentences or phrases, resembling adjective phrases (e.g., “too lengthy”), prepositional phrases (e.g., “to the river”), or nominal phrases (e.g., “the lengthy celebration”).
- Recognizing sentence contexts, sentence relationships, and entities.
- Linguistic textual content evaluation, sentiment evaluation, translations (together with these for voice assistants), chatbots and underlying query and reply programs.
The next are the core elements of NLP:
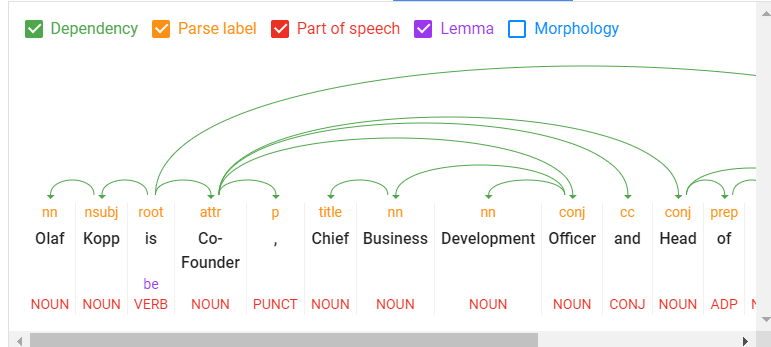
- Tokenization: Divides a sentence into completely different phrases.
- Phrase sort labeling: Classifies phrases by object, topic, predicate, adjective, and so forth.
- Phrase dependencies: Identifies relationships between phrases based mostly on grammar guidelines.
- Lemmatization: Determines whether or not a phrase has completely different types and normalizes variations to the bottom kind. For instance, the bottom type of “vehicles” is “automobile.”
- Parsing labels: Labels phrases based mostly on the connection between two phrases linked by a dependency.
- Named entity evaluation and extraction: Identifies phrases with a “identified” which means and assigns them to lessons of entity varieties. Generally, named entities are organizations, folks, merchandise, locations, and issues (nouns). In a sentence, topics and objects are to be recognized as entities.
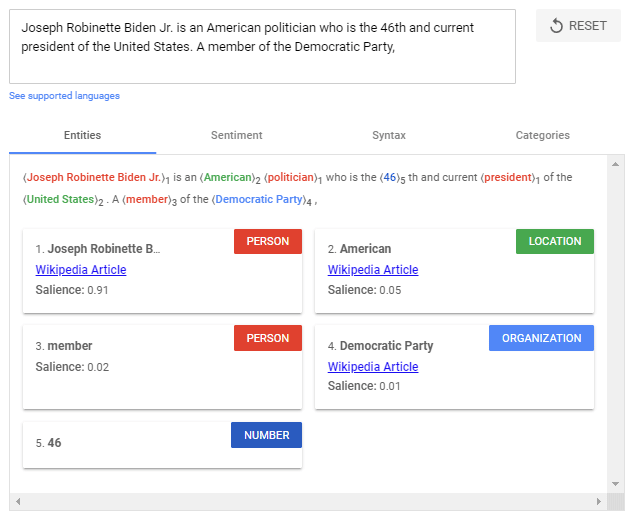
- Salience scoring: Determines how intensively a textual content is linked with a subject. Salience is mostly decided by the co-citation of phrases on the net and the relationships between entities in databases resembling Wikipedia and Freebase. Skilled SEOs know an analogous methodology from TF-IDF evaluation.
- Sentiment evaluation: Identifies the opinion (view or angle) expressed in a textual content in regards to the entities or subjects.
- Textual content categorization: On the macro stage, NLP classifies textual content into content material classes. Textual content categorization helps to find out usually what the textual content is about.
- Textual content classification and performance: NLP can go additional and decide the supposed operate or function of the content material. That is very fascinating to match a search intent with a doc.
- Content material sort extraction: Primarily based on structural patterns or context, a search engine can decide a textual content’s content material sort with out structured information. The textual content’s HTML, formatting, and information sort (date, location, URL, and so forth.) can establish whether or not it’s a recipe, product, occasion or one other content material sort with out utilizing markups.
- Establish implicit which means based mostly on construction: The formatting of a textual content can change its implied which means. Headings, line breaks, lists and proximity convey a secondary understanding of the textual content. For instance, when textual content is displayed in an HTML-sorted listing or a collection of headings with numbers in entrance of them, it’s prone to be a listicle or a rating. The construction is outlined not solely by HTML tags but additionally by visible font dimension/thickness and proximity throughout rendering.
Using NLP in search
For years, Google has educated language fashions like BERT or MUM to interpret textual content, search queries, and even video and audio content material. These fashions are fed through pure language processing.
Google search primarily makes use of pure language processing within the following areas:
- Interpretation of search queries.
- Classification of topic and function of paperwork.
- Entity evaluation in paperwork, search queries and social media posts.
- For producing featured snippets and solutions in voice search.
- Interpretation of video and audio content material.
- Enlargement and enchancment of the Data Graph.
Google highlighted the significance of understanding pure language in search after they launched the BERT replace in October 2019.
“At its core, Search is about understanding language. It’s our job to determine what you’re looking for and floor useful info from the net, regardless of the way you spell or mix the phrases in your question. Whereas we’ve continued to enhance our language understanding capabilities through the years, we generally nonetheless don’t fairly get it proper, notably with complicated or conversational queries. The truth is, that’s one of many the reason why folks typically use “keyword-ese,” typing strings of phrases that they assume we’ll perceive, however aren’t truly how they’d naturally ask a query.”
BERT & MUM: NLP for decoding search queries and paperwork
BERT is claimed to be essentially the most essential development in Google search in a number of years after RankBrain. Primarily based on NLP, the replace was designed to enhance search question interpretation and initially impacted 10% of all search queries.
BERT performs a job not solely in question interpretation but additionally in rating and compiling featured snippets, in addition to decoding textual content questionnaires in paperwork.
“Properly, by making use of BERT fashions to each rating and featured snippets in Search, we’re capable of do a a lot better job serving to you discover helpful info. The truth is, in the case of rating outcomes, BERT will assist Search higher perceive one in 10 searches within the U.S. in English, and we’ll deliver this to extra languages and locales over time.”
The rollout of the MUM replace was introduced at Search On ’21. Additionally based mostly on NLP, MUM is multilingual, solutions complicated search queries with multimodal information, and processes info from completely different media codecs. Along with textual content, MUM additionally understands photographs, video and audio information.
MUM combines a number of applied sciences to make Google searches much more semantic and context-based to enhance the consumer expertise.
With MUM, Google desires to reply complicated search queries in numerous media codecs to affix the consumer alongside the client journey.
As used for BERT and MUM, NLP is an important step to a greater semantic understanding and a extra user-centric search engine.
Understanding search queries and content material through entities marks the shift from “strings” to “issues.” Google’s purpose is to develop a semantic understanding of search queries and content material.
By figuring out entities in search queries, the which means and search intent turns into clearer. The person phrases of a search time period not stand alone however are thought-about within the context of all the search question.
The magic of decoding search phrases occurs in question processing. The next steps are vital right here:
- Figuring out the thematic ontology through which the search question is situated. If the thematic context is evident, Google can choose a content material corpus of textual content paperwork, movies and pictures as probably appropriate search outcomes. That is notably troublesome with ambiguous search phrases.
- Figuring out entities and their which means within the search time period (named entity recognition).
- Understanding the semantic which means of a search question.
- Figuring out the search intent.
- Semantic annotation of the search question.
- Refining the search time period.
Get the day by day e-newsletter search entrepreneurs depend on.
NLP is essentially the most essential methodology for entity mining
Pure language processing will play a very powerful position for Google in figuring out entities and their meanings, making it doable to extract information from unstructured information.
On this foundation, relationships between entities and the Data Graph can then be created. Speech tagging partially helps with this.
Nouns are potential entities, and verbs typically characterize the connection of the entities to one another. Adjectives describe the entity, and adverbs describe the connection.
Google has to date solely made minimal use of unstructured info to feed the Data Graph.
It may be assumed that:
- The entities recorded to date within the Data Graph are solely the tip of the iceberg.
- Google is moreover feeding one other information repository with info on long-tail entities.
NLP performs a central position in feeding this data repository.
Google is already fairly good in NLP however doesn’t but obtain passable ends in evaluating routinely extracted info relating to accuracy.
Knowledge mining for a information database just like the Data Graph from unstructured information like web sites is complicated.
Along with the completeness of the knowledge, correctness is crucial. These days, Google ensures completeness at scale by way of NLP, however proving correctness and accuracy is troublesome.
That is in all probability why Google continues to be performing cautiously relating to the direct positioning of data on long-tail entities within the SERPs.
Entity-based index vs. basic content-based index
The introduction of the Hummingbird replace paved the way in which for semantic search. It additionally introduced the Data Graph – and thus, entities – into focus.
The Data Graph is Google’s entity index. All attributes, paperwork and digital photographs resembling profiles and domains are organized across the entity in an entity-based index.
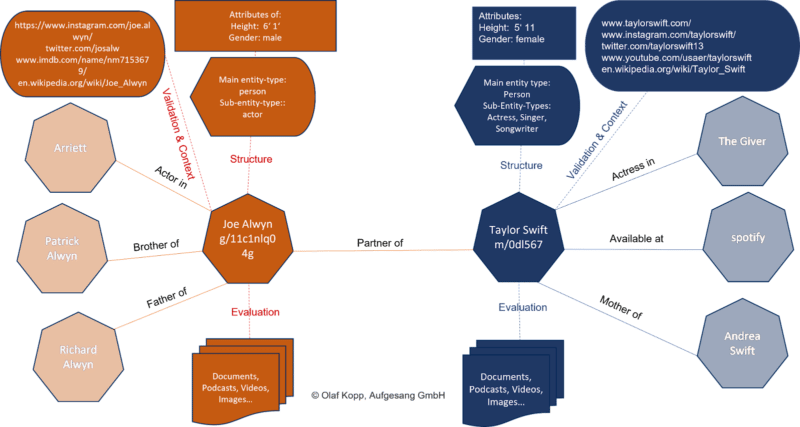
The Data Graph is presently used parallel to the basic Google Index for rating.
Suppose Google acknowledges within the search question that it’s about an entity recorded within the Data Graph. In that case, the knowledge in each indexes is accessed, with the entity being the main focus and all info and paperwork associated to the entity additionally taken into consideration.
An interface or API is required between the basic Google Index and the Data Graph, or one other sort of information repository, to trade info between the 2 indices.
This entity-content interface is about discovering out:
- Whether or not there are entities in a chunk of content material.
- Whether or not there’s a foremost entity that the content material is about.
- Which ontology or ontologies the principle entity could be assigned to.
- Which creator or which entity the content material is assigned.
- How the entities within the content material relate to one another.
- Which properties or attributes are to be assigned to the entities.
It may seem like this:
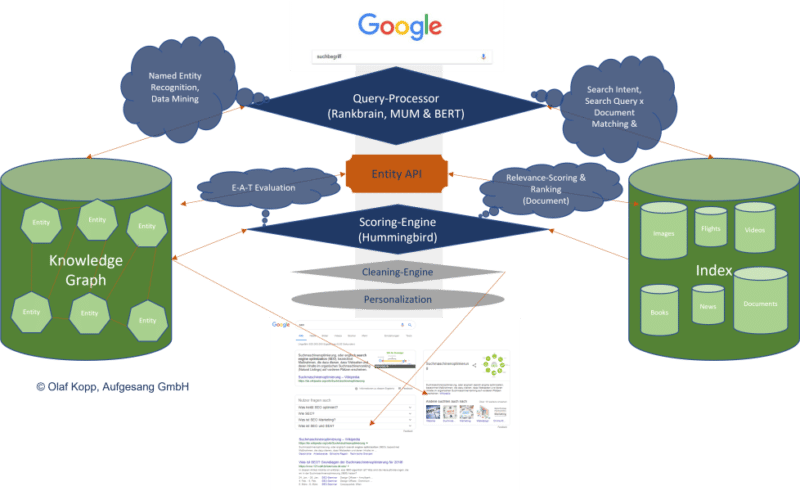
We’re simply beginning to really feel the impression of entity-based search within the SERPs as Google is sluggish to know the which means of particular person entities.
Entities are understood top-down by social relevance. Essentially the most related ones are recorded in Wikidata and Wikipedia, respectively.
The massive activity might be to establish and confirm long-tail entities. It’s also unclear which standards Google checks for together with an entity within the Data Graph.
In a German Webmaster Hangout in January 2019, Google’s John Mueller mentioned they have been engaged on a extra easy option to create entities for everybody.
“I don’t assume we now have a transparent reply. I feel we now have completely different algorithms that verify one thing like that after which we use completely different standards to drag the entire thing collectively, to drag it aside and to acknowledge which issues are actually separate entities, that are simply variants or much less separate entities… However so far as I’m involved I’ve seen that, that’s one thing we’re engaged on to develop {that a} bit and I think about it’ll make it simpler to get featured within the Data Graph as properly. However I don’t know what the plans are precisely.”
NLP performs an important position in scaling up this problem.
Examples from the diffbot demo present how properly NLP can be utilized for entity mining and developing a Data Graph.

NLP in Google search is right here to remain
RankBrain was launched to interpret search queries and phrases through vector house evaluation that had not beforehand been used on this method.
BERT and MUM use pure language processing to interpret search queries and paperwork.
Along with the interpretation of search queries and content material, MUM and BERT opened the door to permit a information database such because the Data Graph to develop at scale, thus advancing semantic search at Google.
The developments in Google Search by way of the core updates are additionally carefully associated to MUM and BERT, and in the end, NLP and semantic search.
Sooner or later, we’ll see increasingly entity-based Google search outcomes changing basic phrase-based indexing and rating.
Opinions expressed on this article are these of the visitor creator and never essentially Search Engine Land. Employees authors are listed right here.
New on Search Engine Land
About The Writer

Olaf Kopp is a web based advertising and marketing skilled with over 15 years of expertise in Google Advertisements, web optimization and content material advertising and marketing. He’s the co-founder, chief enterprise growth officer and head of web optimization on the German on-line advertising and marketing company Aufgesang GmbH. Olaf Kopp is an creator, podcaster and internationally acknowledged business knowledgeable for semantic web optimization, E-A-T, content material advertising and marketing methods, buyer journey administration and digital model constructing. He’s co-organizer of the PPC-Occasion SEAcamp and host of the podcasts OM Cafe and Content material-Kompass (German language).