

{kind=link}
It’s not assured Googlebot will crawl each URL it might entry in your web site. Quite the opposite, the overwhelming majority of web sites are lacking a big chunk of pages.
The fact is, Google doesn’t have the assets to crawl each web page it finds. All of the URLs Googlebot has found, however has not but crawled, together with URLs it intends to recrawl are prioritized in a crawl queue.
This implies Googlebot crawls solely these which can be assigned a excessive sufficient precedence. And since the crawl queue is dynamic, it constantly modifications as Google processes new URLs. And never all URLs be part of behind the queue.
So how do you guarantee your web site’s URLs are VIPs and soar the road?
Crawling is critically vital for Search engine marketing

To ensure that content material to realize visibility, Googlebot has to crawl it first.
However the advantages are extra nuanced than that as a result of the quicker a web page is crawled from when it’s:
- Created, the earlier that new content material can seem on Google. That is particularly vital for time-limited or first-to-market content material methods.
- Up to date, the earlier that refreshed content material can begin to impression rankings. That is particularly vital for each content material republishing methods and technical Search engine marketing ways.
As such, crawling is important for all of your natural site visitors. But too typically it’s mentioned crawl optimization is barely helpful for giant web sites.
Nevertheless it’s not concerning the dimension of your web site, the frequency content material is up to date or whether or not you could have “Found – at present not listed” exclusions in Google Search Console.
Crawl optimization is helpful for each web site. The misunderstanding of its worth appears to spur from meaningless measurements, particularly crawl price range.
Crawl price range doesn’t matter

Too typically, crawling is assessed primarily based on crawl price range. That is the variety of URLs Googlebot will crawl in a given period of time on a selected web site.
Google says it’s decided by two components:
- Crawl price restrict (or what Googlebot can crawl): The pace at which Googlebot can fetch the web site’s assets with out impacting web site efficiency. Primarily, a responsive server results in a better crawl price.
- Crawl demand (or what Googlebot needs to crawl): The variety of URLs Googlebot visits throughout a single crawl primarily based on the demand for (re)indexing, impacted by the recognition and staleness of the positioning’s content material.
As soon as Googlebot “spends” its crawl price range, it stops crawling a web site.
Google doesn’t present a determine for crawl price range. The closest it comes is displaying the whole crawl requests within the Google Search Console crawl stats report.
So many SEOs, together with myself prior to now, have gone to nice pains to attempt to infer crawl price range.
The usually offered steps are one thing alongside the strains of:
- Decide what number of crawlable pages you could have in your web site, typically recommending wanting on the variety of URLs in your XML sitemap or run a limiteless crawler.
- Calculate the typical crawls per day by exporting the Google Search Console Crawl Stats report or primarily based on Googlebot requests in log information.
- Divide the variety of pages by the typical crawls per day. It’s typically mentioned, if the result’s above 10, give attention to crawl price range optimization.
Nonetheless, this course of is problematic.
Not solely as a result of it assumes that each URL is crawled as soon as, when in actuality some are crawled a number of occasions, others in no way.
Not solely as a result of it assumes that one crawl equals one web page. When in actuality one web page might require many URL crawls to fetch the assets (JS, CSS, and many others) required to load it.
However most significantly, as a result of when it’s distilled right down to a calculated metric equivalent to common crawls per day, crawl price range is nothing however a conceit metric.
Any tactic aimed towards “crawl price range optimization” (a.okay.a., aiming to repeatedly enhance the whole quantity of crawling) is a idiot’s errand.
Why must you care about rising the whole variety of crawls if it’s used on URLs of no worth or pages that haven’t been modified for the reason that final crawl? Such crawls gained’t assist Search engine marketing efficiency.
Plus, anybody who has ever checked out crawl statistics is aware of they fluctuate, typically fairly wildly, from at some point to a different relying on any variety of components. These fluctuations might or might not correlate in opposition to quick (re)indexing of Search engine marketing-relevant pages.
An increase or fall within the variety of URLs crawled is neither inherently good nor dangerous.
Crawl efficacy is an Search engine marketing KPI

For the web page(s) that you simply wish to be listed, the main target shouldn’t be on whether or not it was crawled however quite on how shortly it was crawled after being printed or considerably modified.
Primarily, the objective is to reduce the time between an Search engine marketing-relevant web page being created or up to date and the subsequent Googlebot crawl. I name this time delay the crawl efficacy.
The perfect strategy to measure crawl efficacy is to calculate the distinction between the database create or replace datetime and the subsequent Googlebot crawl of the URL from the server log information.
If it’s difficult to get entry to those knowledge factors, you could possibly additionally use as a proxy the XML sitemap lastmod date and question URLs within the Google Search Console URL Inspection API for its final crawl standing (to a restrict of two,000 queries per day).
Plus, through the use of the URL Inspection API you may as well monitor when the indexing standing modifications to calculate an indexing efficacy for newly created URLs, which is the distinction between publication and profitable indexing.
As a result of crawling with out it having a stream on impression to indexing standing or processing a refresh of web page content material is only a waste.
Crawl efficacy is an actionable metric as a result of because it decreases, the extra Search engine marketing-critical content material might be surfaced to your viewers throughout Google.
It’s also possible to use it to diagnose Search engine marketing points. Drill down into URL patterns to grasp how briskly content material from numerous sections of your web site is being crawled and if that is what’s holding again natural efficiency.
In case you see that Googlebot is taking hours or days or perhaps weeks to crawl and thus index your newly created or just lately up to date content material, what are you able to do about it?
Get the every day publication search entrepreneurs depend on.
7 steps to optimize crawling
Crawl optimization is all about guiding Googlebot to crawl vital URLs quick when they’re (re)printed. Comply with the seven steps beneath.
1. Guarantee a quick, wholesome server response
A extremely performant server is important. Googlebot will decelerate or cease crawling when:
- Crawling your web site impacts efficiency. For instance, the extra they crawl, the slower the server response time.
- The server responds with a notable variety of errors or connection timeouts.
On the flip aspect, bettering web page load pace permitting the serving of extra pages can result in Googlebot crawling extra URLs in the identical period of time. That is a further profit on high of web page pace being a consumer expertise and rating issue.
In case you don’t already, contemplate help for HTTP/2, because it permits the flexibility to request extra URLs with an identical load on servers.
Nonetheless, the correlation between efficiency and crawl quantity is barely up to some extent. When you cross that threshold, which varies from web site to web site, any further beneficial properties in server efficiency are unlikely to correlate to an uptick in crawling.
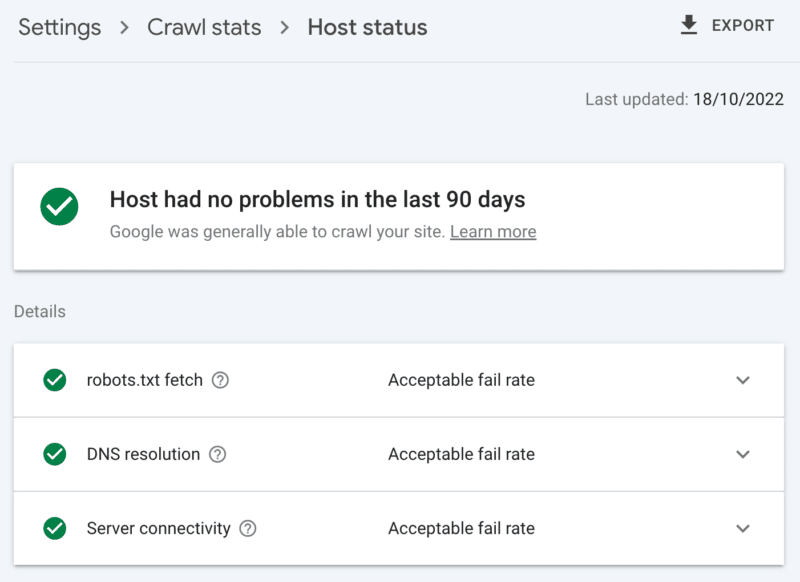
Methods to examine server well being
The Google Search Console crawl stats report:
- Host standing: Exhibits inexperienced ticks.
- 5xx errors: Constitutes lower than 1%.
- Server response time chart: Trending beneath 300 milliseconds.
2. Clear up low-value content material
If a big quantity of web site content material is outdated, duplicate or low high quality, it causes competitors for crawl exercise, probably delaying the indexing of recent content material or reindexing of up to date content material.
Add on that frequently cleansing low-value content material additionally reduces index bloat and key phrase cannibalization, and is helpful to consumer expertise, that is an Search engine marketing no-brainer.
Merge content material with a 301 redirect, when you could have one other web page that may be seen as a transparent substitute; understanding it will value you double the crawl for processing, nevertheless it’s a worthwhile sacrifice for the hyperlink fairness.
If there is no such thing as a equal content material, utilizing a 301 will solely end in a smooth 404. Take away such content material utilizing a 410 (greatest) or 404 (shut second) standing code to offer a robust sign to not crawl the URL once more.
Methods to examine for low-value content material
The variety of URLs within the Google Search Console pages report ‘crawled – at present not listed’ exclusions. If that is excessive, evaluation the samples supplied for folder patterns or different concern indicators.
3. Overview indexing controls
Rel=canonical hyperlinks are a robust trace to keep away from indexing points however are sometimes over-relied on and find yourself inflicting crawl points as each canonicalized URL prices at the least two crawls, one for itself and one for its accomplice.
Equally, noindex robots directives are helpful for decreasing index bloat, however a big quantity can negatively have an effect on crawling – so use them solely when crucial.
In each instances, ask your self:
- Are these indexing directives the optimum strategy to deal with the Search engine marketing problem?
- Can some URL routes be consolidated, eliminated or blocked in robots.txt?
If you’re utilizing it, severely rethink AMP as a long-term technical answer.
With the web page expertise replace specializing in core internet vitals and the inclusion of non-AMP pages in all Google experiences so long as you meet the positioning pace necessities, take a tough have a look at whether or not AMP is well worth the double crawl.
Methods to examine over-reliance on indexing controls
The variety of URLs within the Google Search Console protection report categorized below the exclusions with no clear motive:
- Various web page with correct canonical tag.
- Excluded by noindex tag.
- Duplicate, Google selected completely different canonical than the consumer.
- Duplicate, submitted URL not chosen as canonical.
4. Inform search engine spiders what to crawl and when
A vital device to assist Googlebot prioritize vital web site URLs and talk when such pages are up to date is an XML sitemap.
For efficient crawler steerage, you should definitely:
- Solely embody URLs which can be each indexable and helpful for Search engine marketing – usually, 200 standing code, canonical, authentic content material pages with a “index,observe” robots tag for which you care about their visibility within the SERPs.
- Embrace correct <lastmod> timestamp tags on the person URLs and the sitemap itself as near real-time as attainable.
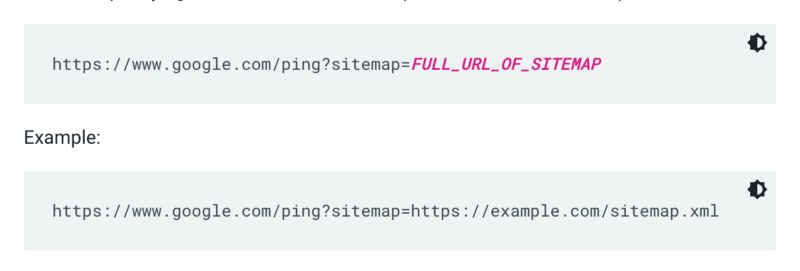
Google would not examine a sitemap each time a web site is crawled. So each time it’s up to date, it’s greatest to ping it to Google’s consideration. To take action ship a GET request in your browser or the command line to:
Moreover, specify the paths to the sitemap within the robots.txt file and submit it to Google Search Console utilizing the sitemaps report.
As a rule, Google will crawl URLs in sitemaps extra typically than others. However even when a small share of URLs inside your sitemap is low high quality, it might dissuade Googlebot from utilizing it for crawling strategies.
XML sitemaps and hyperlinks add URLs to the common crawl queue. There may be additionally a precedence crawl queue, for which there are two entry strategies.
Firstly, for these with job postings or stay movies, you’ll be able to submit URLs to Google’s Indexing API.
Or if you wish to catch the attention of Microsoft Bing or Yandex, you need to use the IndexNow API for any URL. Nonetheless, in my very own testing, it had a restricted impression on the crawling of URLs. So should you use IndexNow, you should definitely monitor crawl efficacy for Bingbot.
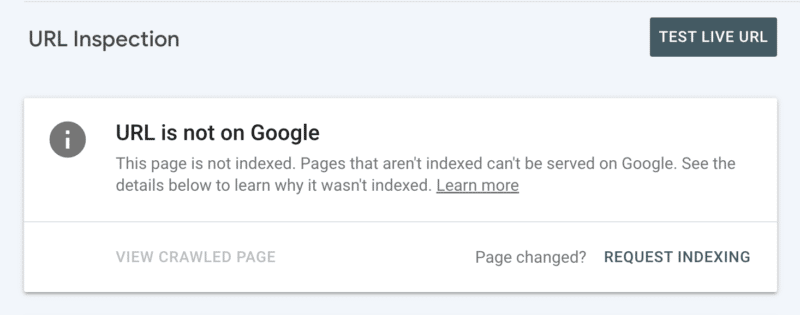
Secondly, you’ll be able to manually request indexing after inspecting the URL in Search Console. Though remember there’s a every day quota of 10 URLs and crawling can nonetheless take fairly some hours. It’s best to see this as a brief patch when you dig to find the basis of your crawling concern.
Methods to examine for important Googlebot do crawl steerage
In Google Search Console, your XML sitemap reveals the standing “Success” and was just lately learn.
5. Inform search engine spiders what to not crawl
Some pages could also be vital to customers or web site performance, however you don’t need them to seem in search outcomes. Stop such URL routes from distracting crawlers with a robots.txt disallow. This might embody:
- APIs and CDNs. For instance, in case you are a buyer of Cloudflare, you should definitely disallow the folder /cdn-cgi/ which is added to your web site.
- Unimportant pictures, scripts or model information, if the pages loaded with out these assets will not be considerably affected by the loss.
- Purposeful web page, equivalent to a procuring cart.
- Infinite areas, equivalent to these created by calendar pages.
- Parameter pages. Particularly these from faceted navigation that filter (e.g., ?price-range=20-50), reorder (e.g., ?kind=) or search (e.g., ?q=) as each single mixture is counted by crawlers as a separate web page.
Be aware to not utterly block the pagination parameter. Crawlable pagination up to some extent is usually important for Googlebot to find content material and course of inside hyperlink fairness. (Try this Semrush webinar on pagination to be taught extra particulars on the why.)
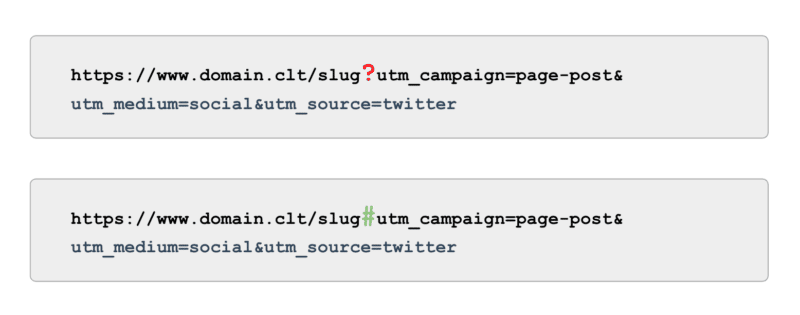
And on the subject of monitoring, quite than utilizing UTM tags powered by parameters (a.okay.a., ‘?’) use anchors (a.okay.a., ‘#’). It provides the identical reporting advantages in Google Analytics with out being crawlable.
Methods to examine for Googlebot don’t crawl steerage
Overview the pattern of ‘Listed, not submitted in sitemap’ URLs in Google Search Console. Ignoring the primary few pages of pagination, what different paths do you discover? Ought to they be included in an XML sitemap, blocked from being crawled or let be?
Additionally, evaluation the listing of “Found – at present not listed” – blocking in robots.txt any URL paths that provide low to no worth to Google.
To take this to the subsequent stage, evaluation all Googlebot smartphone crawls within the server log information for worthless paths.
6. Curate related hyperlinks
Backlinks to a web page are helpful for a lot of points of Search engine marketing, and crawling isn’t any exception. However exterior hyperlinks might be difficult to get for sure web page sorts. For instance, deep pages equivalent to merchandise, classes on the decrease ranges within the web site structure and even articles.
However, related inside hyperlinks are:
- Technically scalable.
- Highly effective indicators to Googlebot to prioritize a web page for crawling.
- Significantly impactful for deep web page crawling.
Breadcrumbs, associated content material blocks, fast filters and use of well-curated tags are all of great profit to crawl efficacy. As they’re Search engine marketing-critical content material, guarantee no such inside hyperlinks are depending on JavaScript however quite use a normal, crawlable <a> hyperlink.
Taking into account such inside hyperlinks also needs to add precise worth for the consumer.
Methods to examine for related hyperlinks
Run a handbook crawl of your full web site with a device like ScreamingFrog’s Search engine marketing spider, searching for:
- Orphan URLs.
- Inside hyperlinks blocked by robots.txt.
- Inside hyperlinks to any non-200 standing code.
- The proportion of internally linked non-indexable URLs.
7. Audit remaining crawling points
If the entire above optimizations are full and your crawl efficacy stays suboptimal, conduct a deep dive audit.
Begin by reviewing the samples of any remaining Google Search Console exclusions to establish crawl points.
As soon as these are addressed, go deeper through the use of a handbook crawling device to crawl all of the pages within the web site construction like Googlebot would. Cross-reference this in opposition to the log information narrowed right down to Googlebot IPs to grasp which of these pages are and aren’t being crawled.
Lastly, launch into log file evaluation narrowed right down to Googlebot IP for at the least 4 weeks of information, ideally extra.
If you’re not acquainted with the format of log information, leverage a log analyzer device. Finally, that is the most effective supply to grasp how Google crawls your web site.
As soon as your audit is full and you’ve got a listing of recognized crawl points, rank every concern by its anticipated stage of effort and impression on efficiency.
Notice: Different Search engine marketing consultants have talked about that clicks from the SERPs enhance crawling of the touchdown web page URL. Nonetheless, I’ve not but been in a position to verify this with testing.
Prioritize crawl efficacy over crawl price range
The objective of crawling is to not get the very best quantity of crawling nor to have each web page of an internet site crawled repeatedly, it’s to entice a crawl of Search engine marketing-relevant content material as shut as attainable to when a web page is created or up to date.
Total, budgets don’t matter. It’s what you make investments into that counts.
Opinions expressed on this article are these of the visitor writer and never essentially Search Engine Land. Employees authors are listed right here.
New on Search Engine Land
About The Creator
Jes Scholz leads a crew liable for the institution of promoting greatest practices and transferring learnings globally throughout Swiss media large Ringier’s various portfolio of manufacturers. Jes spends a lot of her time testing theories on the way forward for search, main tasks in chatbots, laptop imaginative and prescient, digital actuality, AI for automation and the rest that may future proof manufacturers. A robust believer in data-driven advertising and agile methodologies, she is at all times testing out new ways with the assistance of her crew.